Disclaimer: This blog post was inspired by David Kunnen's case study on how to disable JavaScript for GoogleBot. The immense value of his insights inspired me to explore the subject in more depth, learn about it, and document my findings in this post.
As of 2023, JavaScript is the most popular programming language—accounting for around 63.61% of all languages. Its dynamic nature allows it to pull information from databases, APIs, and other sources, rendering this data on the front end of web applications. This cross-platform compatibility reduces implementation costs across multi‑channel projects, and its smooth, natural feel has become visually appealing—unlike some lagging HTML/CSS applications (although advanced CSS can be quite beautiful at an elite level).
Introducing The Problem: Outside Fetching
I have a personal mantra: "Our greatest strength is also our greatest weakness." JavaScript is no different. Because it frequently fetches information from external sources and then injects it on the client side, JavaScript usually loads last. Here's a simplified process:
- You visit a webpage.
- Your action contacts the server.
- The server sends back the files to load the page.
- A framework is built to save resources, which is then "filled out."
- The final parts to load are often the JavaScript elements.
For SEO and GoogleBot, let's assume JavaScript is processed last—and this is where the problems begin.
How Google Processes JavaScript
It's well documented that Google takes 8x to 9x longer to process JavaScript compared to regular HTML/CSS.
This is due to the following, the JavaScript processing pipeline officially documented by Google:
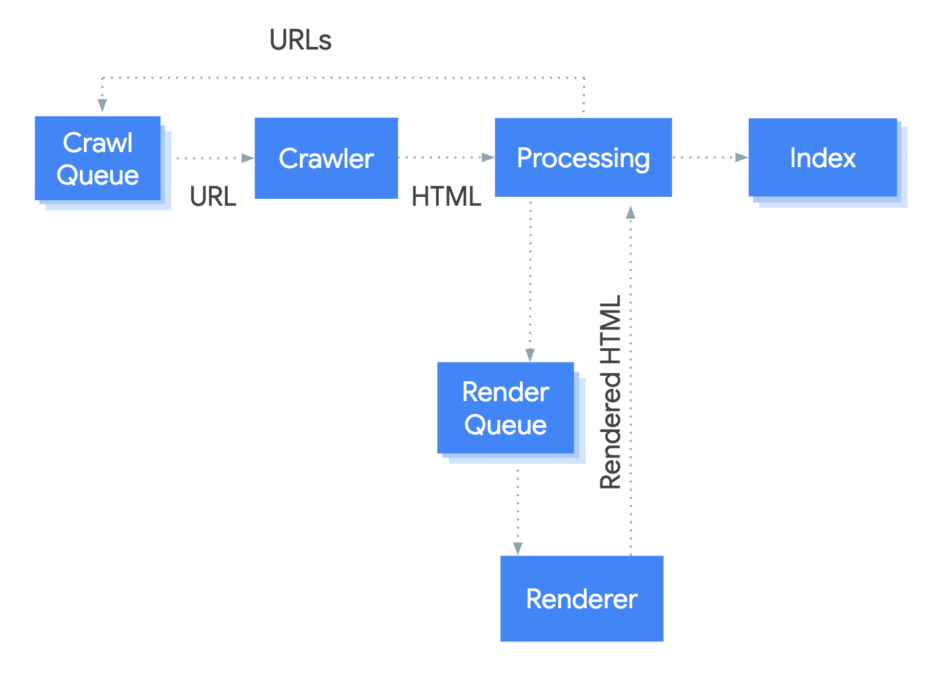
Google's JavaScript processing pipeline can be broken down into three main phases:
- Crawling: Google first discovers links, building a map of your site.
- Rendering: Discovered pages are queued and processed using a headless Chromium browser, which converts dynamic JavaScript elements into static HTML/CSS.
- Indexing: Once rendered, the static content is indexed.
Remember, Google is a business with finite computing resources. Processing JavaScript is resource‑intensive; therefore, if we want to benefit from strong SEO performance while using JavaScript, we need to make some adjustments.
The Solution: Making JavaScript Easier To Render
There are multiple strategies to ease the rendering of JavaScript by Google. In this post, we'll focus on three approaches:
- Server‑side Rendering (SSR)
- Using Auto‑Generating, Dynamic Sitemaps
- Disabling GoogleBot from Crawling JavaScript
Let's explore each one.
Server‑side Rendering (SSR)
While I won't cover SSR in exhaustive detail here (I plan to write future posts on this topic), the basic idea is to render JavaScript on the server. This means that when a request is made, only static HTML and CSS are served—ideal for websites that rely heavily on JavaScript to produce content and interactive features. SSR is particularly common in eCommerce sites, headless CMS platforms, and modern blogs that employ fluid, cutting‑edge design.
Using Auto‑Generating, Dynamic Sitemaps
Another smart implementation—highlighted in Kunnen's guide—is the use of dynamic, auto‑generating sitemaps. In a typical setup, a sitemap updates with changes in site hierarchy, but here the sitemap is split into segments of 50,000 lines (in accordance with Google's documentation). These segmented sitemaps are automatically uploaded to a CDN and refreshed in Google Search Console twice a day. The result is faster processing and crawling, as well as increased crawl requests and quicker indexation.
Telling GoogleBot NOT To Crawl JavaScript
Even with SSR and dynamic sitemaps, GoogleBot may still queue JavaScript files for rendering. Since our implementation now serves static HTML/CSS to bots, we can prevent unnecessary JavaScript crawling. Add the following code snippet to your server's application logic (typically found in the 'app.js', 'server.js' or 'index.js' files at the root of your project.
if(isBot(req)) {
completeHtml = completeHtml.replace(/<script[^>]+>(?:(?!<\/script>)[^])*<\/script>/g, '');
}
The script works in the following way:
-
if(isBot(req)): This checks if the incoming request (req) is from a bot. TheisBotfunction would need to be defined elsewhere in your code to make this determination. -
completeHtml = completeHtml.replace(...): This line modifies thecompleteHtmlvariable, which presumably contains the HTML of the page to be served. -
The regex
/<script[^>]*>(?:(?!<\/script>)[^])*<\/script>/gis used in the replace function. This regex matches<script>tags and their contents in the HTML. Here's how:<script[^>]*>: Matches the opening<script>tag.[^>]*matches any character except>any number of times, to include attributes in the script tag.(?:(?!<\/script>)[^])*: This is a bit complex. It's a non-capturing group that matches any character sequence that is not the closing tag.<\/script>: Matches the closing</script>tag.- The
gat the end is a flag that tells the regex engine to perform a global search, replacing all matches in the string, not just the first one.
The overall effect is that it searches for and removes all <script> tags (and their contents) from the completeHtml string. This is typically used to serve a version of the page without JavaScript to bots, which can help with SEO and page indexing.
Now that we're not rendering any JavaScript to bots, Google is quickly able to crawl and parse only HTML/CSS files that are important for page content—and doesn't waste time recrawling JavaScript files that can clog up the crawl queue.
Conclusion
I would argue that the average SEO doesn't really consider how JavaScript is impacting their projects.
Furthermore, ever fewer SEOs have the experience or skills required to successfully guide an SSR implementation, taking into account the business use case for that particular website.
And lastly, I'm not sure that many would consider even turning off crawling for JavaScript from Google's in order to preserve crawl resources so that it's focused on relative pages.
It's for this reason that I wanted to create this guide, as I feel it would serve the right SEO well and lead to a lot of success when done correctly.
I'll float this with a caveat, that is an advanced level implementation and shouldn't be done without proper planning or technical experience.
On a practical level, disabling JavaScript for GoogleBot could be really bad for the wrong website. It might be advised to only implement this on particular pages, templates or site sections—just so that Google has the option to crawl JavaScript on certain pages on the website.